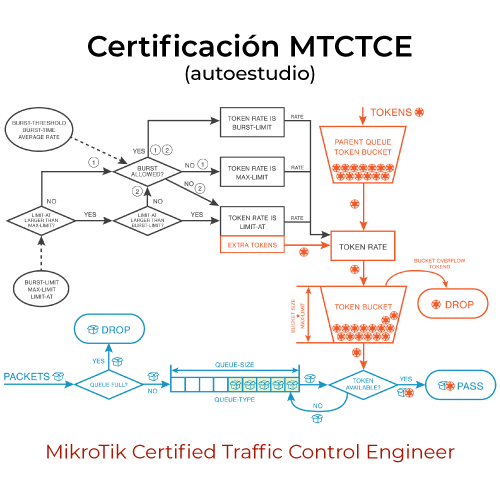
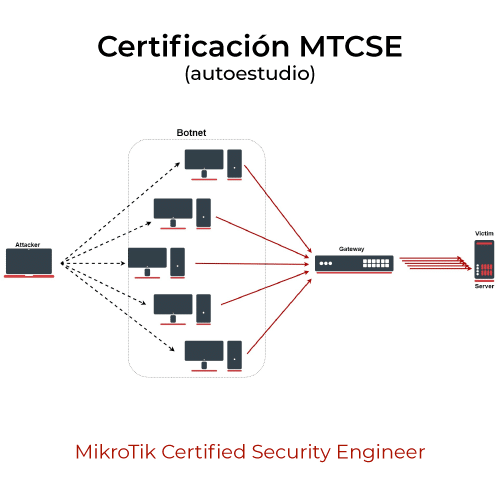
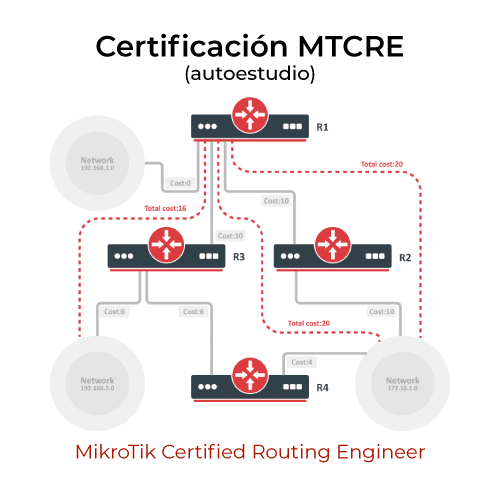
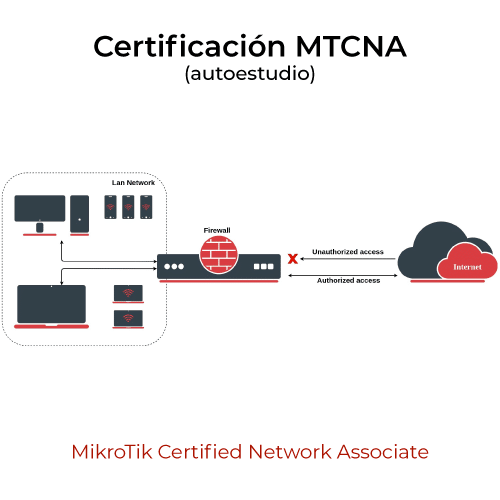
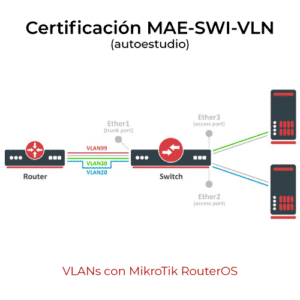
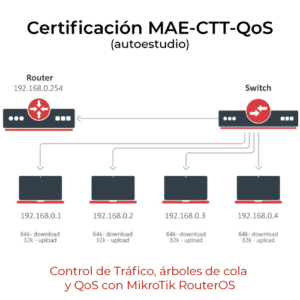
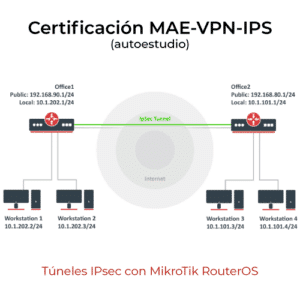
La ciencia de datos es una disciplina poderosa y en constante evolución. Para dar un mayor entendimiento sobre su proceso y cómo se aplica, es útil describir las etapas que suelen llevarse a cabo en un proyecto de ciencia de datos:
1. Definición de la pregunta o problema
Todo proyecto de ciencia de datos comienza con una pregunta o un problema que necesita ser resuelto.
Esta fase implica la identificación de las metas del proyecto y las preguntas que se quieren responder.
2. Adquisición de los datos
Una vez que se ha definido la pregunta o problema, el siguiente paso es la adquisición de los datos necesarios para responder a esas preguntas.
Esto puede involucrar la recopilación de datos primarios a través de encuestas o experimentos, o la adquisición de datos secundarios a través de bases de datos existentes, archivos, feeds de internet, redes sociales, etc.
3. Limpieza y preparación de los datos
Los datos rara vez vienen en un formato perfecto para el análisis. En esta etapa, los datos se limpian y preparan para el análisis.
Esto puede implicar el manejo de datos faltantes, la detección y corrección de errores, la transformación de variables, la codificación de datos categóricos, etc.
4. Exploración de los datos
Esta etapa implica la exploración de los datos para obtener una comprensión de las características y patrones de los datos.
Esto se hace a través de métodos estadísticos y visualizaciones de datos.
5. Modelado de los datos
En esta etapa, se construyen modelos matemáticos o computacionales para responder a las preguntas o problemas definidos en la primera etapa.
Esto puede implicar el uso de técnicas de aprendizaje automático, estadísticas, o incluso el desarrollo de algoritmos personalizados.
6. Evaluación del modelo
Después de construir el modelo, la siguiente etapa es evaluar su rendimiento. Esto implica el uso de métricas de rendimiento adecuadas y la validación de los resultados a través de técnicas como la validación cruzada o el conjunto de pruebas.
7. Interpretación de los resultados
Una vez que se ha evaluado el modelo, el siguiente paso es interpretar los resultados y extraer conclusiones.
Esta etapa puede implicar la visualización de los resultados, la realización de pruebas de significación estadística, y la interpretación de los coeficientes del modelo o las características de importancia.
8. Comunicación de los resultados
La última etapa del proyecto es la comunicación de los resultados a las partes interesadas.
Esto puede implicar la creación de informes, presentaciones, dashboards, o incluso la publicación de los resultados en revistas científicas o blogs.
9. Implementación y seguimiento
En muchos proyectos, después de la fase de comunicación, se lleva a cabo una implementación del modelo en un entorno en vivo y se hace un seguimiento de su rendimiento a lo largo del tiempo, haciendo ajustes y mejoras si es necesario.
Este proceso es iterativo. Con base en los hallazgos y resultados, se pueden formular nuevas preguntas, lo que puede llevar a la adquisición de nuevos datos y la creación de nuevos modelos, y el ciclo se repite.
Es importante destacar que la ciencia de datos no es solo acerca de la matemática y la programación, también implica una gran cantidad de habilidades de pensamiento crítico, resolución de problemas y comunicación. Los buenos científicos de datos son capaces de entender el contexto del problema que están tratando de resolver, hacer preguntas inteligentes acerca de los datos, y comunicar sus hallazgos de una manera clara y persuasiva.